
Die Anonymisierung personenbezogener Daten stellt Verantwortliche immer wieder vor komplexe Herausforderungen.
Als Goldstandard taucht daher hier oftmals der Begriff „Differential Privacy“ auf, den wir hier genauer betrachten möchten.
Übersicht
Stand der Technik
Der Stand der Technik bezieht sich auf den aktuellen Fortschritt und die Entwicklung in einem bestimmten Bereich der Technologie oder einem Fachgebiet. Er umfasst die aktuellen Technologien, Verfahren und Methoden, die in einem Bereich verwendet werden, sowie die wissenschaftlichen Erkenntnisse und Ergebnisse, die in diesem Bereich erzielt wurden. Der Stand der Technik dient als Referenzpunkt und Basis für zukünftige Entwicklungen und Fortschritte in einem Bereich. Er wird häufig in Patentanträgen und wissenschaftlichen Publikationen zitiert, um zu zeigen, wie eine bestimmte Erfindung oder ein bestimmtes Verfahren im Vergleich zu dem steht, was derzeit bereits bekannt ist und verwendet wird.
Auch Differential Privacy erfüllt mittlerweile die genannten Voraussetzungen.
Vor allem im Bereich der Produktentwicklung und Forschung wird zunehmend auf die Anonymisierung personenbezogener Daten zurückgegriffen. Der Clou dabei: anonymisierte Daten sind keine personenbezogenen Daten und unterliegen daher auch nicht der DSGVO. Gleichzeitig zeigen aber auch einige Presseberichterstattungen auf, dass eine De-Anonymisierung oft viel leichter als vermutet vorgenommen werden kann. Nach einer Arbeit der Carnegie-Mellon-Universität (von 1990) ist demnach fast jeder US-Amerikaner lediglich durch das Geschlecht, das Geburtsdatum und seine Postleitzahl zu identifizieren. Die hier vorhandenen Rahmenbedingungen zeigen, dass dies in Deutschland so nicht möglich wären. Dennoch ist und bleibt die Frage, ab wann bzw. ob personenbezogene Daten jemals wirklich anonym sind.
Anonyme Daten
Die Frage, ob und wann Daten wirklich anonym und eben nicht mehr zur Identifizierung einer Person einsetzbar sind, muss jeder Verantwortliche im Rahmen seiner Rechenschaftspflicht selbst beantworten können. Denn gerade bei der Anonymisierung größerer Datenmengen und / oder sensibler Datenmengen werden Aufsichtsbehörden sehr schnell hellhörig. Auch besteht hier die Pflicht zur Vornahme einer Datenschutzfolgenabschätzung.
Die DSGVO gibt nur wenige klare Aussagen zur Anonymisierung, weshalb bei der Wahl der Anonymisierungsmethode viel Freiraum besteht. Beim Ergebnis gibt es diesen Spielraum allerdings nicht: aus den anonymisierten Daten dürfen keine Personen identifiziert werden.
Differential Privacy
„Differential Privacy“ (engl. ‚differentielle Privatsphäre‘) ist an dieser Stelle keine Vorgehensweise zur Anonymisierung, sondern vielmehr ein „Datenschutzversprechen“ mit dem mathematisch belegt wird, dass das vorhandene Restrisiko der De-Anonymisierung zwar vorhanden, aber gering und tolerabel ist.
Dies soll am folgenden Bild gezeigt werden:
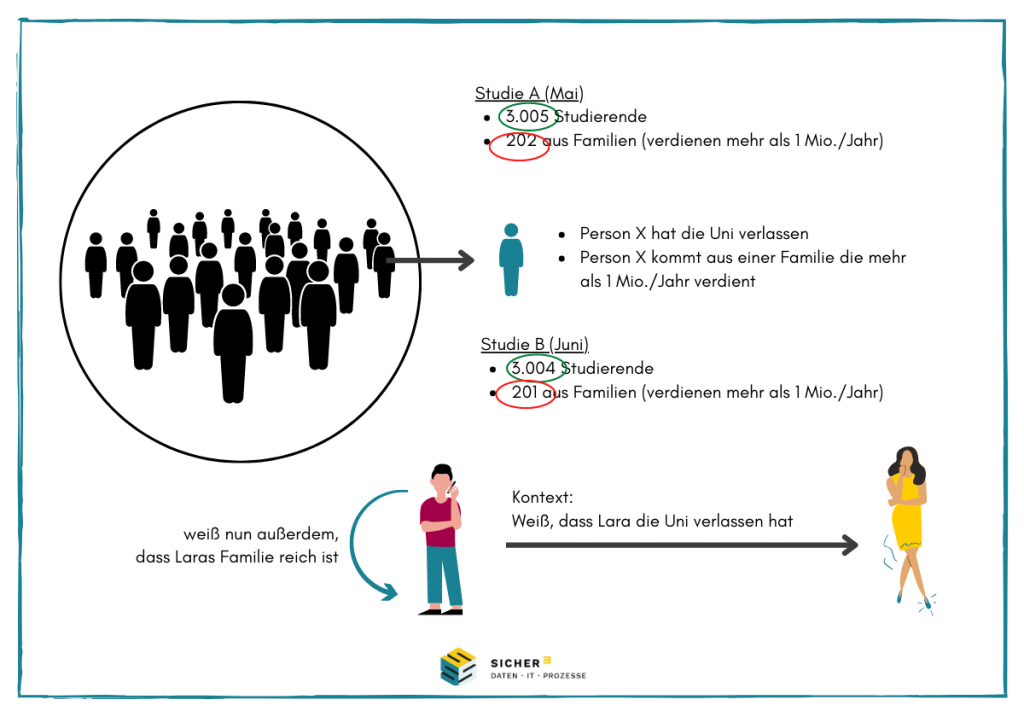
In der Studie A sind 3.005 Studierende an einer Uni eingeschrieben. Davon kommen 202 Studierende aus Familien, die mehr als 1 Million im Jahr verdienen. Mit diesen Informationen lässt sich nicht identifizieren, wer aus einer reicheren Familie kommt und wer nicht.
Wenn man annimmt, das Person X die Uni verlässt und die Studie einen Monat später erneut durchgeführt wird, scheint auch dann das Ergebnis zunächst anonym zu sein. Vergleicht man die beiden Studien, wird klar, dass Person X aus einer reichen Familie kommt.
Und dennoch weiß jeder, der die Studien sieht und auch weiß, wer die Uni verlassen hat (hier: Lara), nun auch, dass Lara aus einer reichen Familie kommt.
Das hier vorliegende Problem nennt sich „Kompositionsproblem„: einzeln betrachtet erscheint die Lage unproblematisch. Durch Verknüpfung mit Zusatzwissen entsteht ein höherer Informationsgehalt, wodurch sich Daten de-anonymisieren lassen. Und genau diese Problematik wird durch Differential Privacy adressiert, denn nahezu jeder Anonymisierungsvorgang enthält Informationen über eine Person, auch wenn diese alleine betrachtet nicht identifiziert werden kann.
Die Lösung hierfür nennt sich „Rauschen“ und wird durch den Privacy-Loss-Parameter ε festgelegt. Dieser sorgt dafür, dass an eine Datenbasis zeitversetzt mehrere Anonymisierungsvorgänge gestellt werden und leicht verfälschte Daten zurückgegeben werden. Hierdurch wird gewährleistet, dass die Ergebnisse einer statistischen Analyse nicht dazu verwendet werden können, festzustellen, ob die Daten einer bestimmten Person in die Analyse einbezogen wurden oder nicht. Dies wird erreicht, indem den Daten zufälliges Rauschen hinzugefügt wird, so dass die statistische Genauigkeit der Ergebnisse erhalten bleibt, es aber schwierig oder unmöglich ist, den Beitrag eines einzelnen Datenpunkts zu den Ergebnissen zu bestimmen. Differentieller Datenschutz wird häufig im Zusammenhang mit Datenschutz und Sicherheit verwendet und findet in vielen Bereichen Anwendung, darunter im Gesundheitswesen, im Finanzwesen und in den sozialen Medien.
Privacy Budget
Der Begriff „Privacy Budget“ bezieht sich auf die Menge an Informationen, die eine Organisation bereit ist, weiterzugeben, um ein gewünschtes Maß an Privatsphäre zu erhalten. Dieses Konzept wurde eingeführt, um Organisationen dabei zu helfen, die Vorteile der Erhebung und Nutzung personenbezogener Daten und die Risiken für die Privatsphäre des Einzelnen gegeneinander abzuwägen.
Um ein Datenschutzbudget festzulegen, müssen Unternehmen Faktoren wie die Sensibilität der zu erfassenden Daten, die potenziellen Risiken für Einzelpersonen bei unsachgemäßem Umgang mit den Daten und den potenziellen Nutzen der Datenerfassung und -nutzung berücksichtigen. Anhand des Datenschutzbudgets können dann Entscheidungen darüber getroffen werden, wie viele Daten gesammelt werden sollen, wie sie verwendet und wie sie geschützt werden.
Ein Unternehmen kann beispielsweise beschließen, dass es bereit ist, einige personenbezogene Daten weiterzugeben, um einen stärker personalisierten Service anzubieten, kann aber Grenzen für die Menge der gesammelten Daten und deren Verwendung festlegen, um die Privatsphäre seiner Kunden zu schützen.
Fazit
Eine Anonymisierung ist ein komplexer Sachverhalt und zieht außerdem das Risiko mit sich, die Aufmerksamkeit der Aufsichtsbehörde auf sich zu ziehen. Es wird daher empfohlen:
- Die Methoden zur Anonymisierung sollten dem Stand der Technik entsprechen. Das Löschen von Namen und Adressen beispielsweise ist nicht ausreichend. Fragen Sie nach den Begriffen „k-Anonymität“, „T-Geschlossenheit“ und „L-Diversität“.
- Weiter sollte das Vorhandensein der Differential-Privacy-Eigenschaft geprüft werden. Der Epsilon-Wert sollte hierbei zwischen 0 und 1 liegen.
- Außerdem muss eine DSFA durchgeführt werden. Diese analysiert die Punkte 1 und 2.
Der methodische Aufwand ist hoch. Oft lohnt es sich daher dennoch an den Inhalten der DSGVO zu orientieren.
Sollten Sie weitere Unterstützung oder Beratung benötigen, melden Sie sich gerne bei uns.
Quelle: Viele der Gedanken hier und die ursprüngliche Grafik haben wir aus der Zeitschrift „Datenschutz-Praxis“, Ausgabe 09/2022